

近幾個月以來,隨著 ChatGPT, Dall-E, Bing Chat, Stable Diffusion, Bard, MidJourney... 等等的 AIGC 工具不斷推出,本來兩個月前已想寫這篇文章,由於發展速度實在太快,每天都在不斷地學習,所以今天才開始陸續做一些總結。
今次先分享個人對提示工程 Prompt Engineering 的理解。

Photo Credit: https://effectivesoftwaredesign.com/
提示工程 Prompt Engineering
使用 ChatGPT 或同類型 LLM (大型語言模型 Large Language Model)的時候,有些人會得到預期或更佳答案,但也有部份人會認為答案不如預期,出現這種情況的原因很大程度是
「沒有掌握向 LLM 發問的技巧!」
亦即如果使用一些發問技巧,學會如何與 LLM 打交道,將會從 LLM 得到預期的結果。
而這些發問技巧,就是 提示 Prompt!而如何設計合適的 Prompt?這就是 Prompt Engineering 提示工程。
更簡單的理解是:透過設計合適的 Prompt 去為 LLM 提供一些基礎背景情況,條件及限制、輸出的要求等等,令 LLM 更清楚"理解"我們的實際指令,這樣才能得到更優質的輸出結果。
相信大家最近也會經常看到一些 Prompt 提示詞:
例如「你扮演某方面的專家,你熟悉某個領域的知識......等等」,這些在本身上就是在"引導" LLM,這其實是有原因的,因為這些 LLM 在訓練的時候,所使用的訓練方式、訓練的數據都不一樣,而且內容的質量高低如是。
根據 LLM 背後原理,"引導" LLM 實際上就是讓 LLM 盡可能地在生成時,將挑選接下來的字,概率分佈在相關的數據內容上,以令最終生成結果更符合預期。
那麼,如何為 ChatGPT 等 LLM 設計出合適的 Prompt?
OpenAI 官方 和 Andrew Ng(吳恩達) 也給出了一些方法和思路,這是原文超鏈結:
OpenAI 《Best practices for prompt engineering with OpenAI API》
Deeplarning.ai 《ChatGPT Prompt Engineering for Developers》
以下是一些我對以上內容的一些總結和思考,並使用官方的例子:
Prompting Principles 提示主要原則
1. 編寫清晰及特定的指引
2. 給予模型時間進行"思考"
Prompting Principles 提示技巧
1. 針對生成結果選擇最新且合適的模型
通常建議使用最新且合適的模型。
例如文本生成,截至2022年11月,在 OpenAI 上最佳選擇的是"text-davinci-003"。
但如果是代碼生成,則最佳選擇是"code-davinci-002"。
最合適的選擇是基於任務選擇用於生成的模型
2. 使用 Delimiter(分隔符)區分指令和上下文
將指令放在「內容」前面,並且使用 ###, """, ```, ''', <tag></tag>... 等等的類似的分隔符區別指令和上下文。
低效 ❌:
Summarize the text below as a bullet point list of the most important points.
{text input here}
更佳 ✅:
Summarize the text below as a bullet point list of the most important points.
Text: """
{text input here}
"""
可以看到例子中的是用了一對(三個雙引號 """ )明確地指定這個部份是內容,以令 LLM 更清晰哪個部份是指令,哪個部份是內容。
3. 要更具體地、有效描述所需要的結果,例如結果的長度、格式、風格等等
低效 ❌:
Write a poem about OpenAI.
更佳 ✅:
Write a short inspiring poem about OpenAI, focusing on the recent DALL-E product launch (DALL-E is a text to image ML model) in the style of a {famous poet}
越有效、越精確的提示越好!
4. 提供一些例子明確輸出格式
低效 ❌:
Extract the entities mentioned in the text below. Extract the following 4 entity types: company names, people names, specific topics and themes.
Text: {text}
更佳 ✅:
Extract the important entities mentioned in the text below. First extract all company names, then extract all people names, then extract specific topics which fit the content and finally extract general overarching themes
Desired format:
Company names: <comma_separated_list_of_company_names>
People names: -||-
Specific topics: -||-
General themes: -||-Text: {text}
當顯示特定的格式的要求的時候,模型的回應會更好!
5. "Few-shot" prompting
提供一個或數個「例子」供 模型參考

提供「例子」給模型參考,它將會更好地理解需要輸出內容的風格和要求
6. 指定完成任務所需的步驟
一步一步列明所需要執行的步驟

7. 混合樣本提示
即先嘗試零樣本提示(Zero-Shot),再進行少樣本提示(Few-Shots),如果兩種都不起作用,再進行微調(Fine-tune)
- 零樣本提示(Zero-Shot)
Extract keywords from the below text.
Text: {text}
Keywords:
- 少樣本提示(Few-Shots)
Extract keywords from the corresponding texts below.
Text 1: Stripe provides APIs that web developers can use to integrate payment processing into their websites and mobile applications.
Keywords 1: Stripe, payment processing, APIs, web developers, websites, mobile applications
##
Text 2: OpenAI has trained cutting-edge language models that are very good at understanding and generating text. Our API provides access to these models and can be used to solve virtually any task that involves processing language.
Keywords 2: OpenAI, language models, text processing, API.
##
Text 3: {text}
Keywords 3:
- 微調(Fine-tune)
可以參考這篇教學
8. 減少"瑣碎"和不精確的描述
低效 ❌:
The description for this product should be fairly short, a few sentences only, and not too much more.
更佳 ✅:
Use a 3 to 5 sentence paragraph to describe this product.
提示並不是越多越好,而是合理地、有效、精確描述,比起大量無意義來得更有效率。
9. 說明應該做什麼,而不只是說不要做什麼
低效 ❌:
The following is a conversation between an Agent and a Customer. DO NOT ASK USERNAME OR PASSWORD. DO NOT REPEAT.
Customer: I can’t log in to my account.
Agent:
更佳 ✅:
The following is a conversation between an Agent and a Customer. The agent will attempt to diagnose the problem and suggest a solution, whilst refraining from asking any questions related to PII. Instead of asking for PII, such as username or password, refer the user to the help article www.samplewebsite.com/help/faq
Customer: I can’t log in to my account.
Agent:
應該要參考思維鏈提示的技術(Chain-of-thought),提示 LLM 一系列的步驟,引導 LLM 進行推理,從而提出更佳結果。
10. 具體代碼生成 - 使用「引導詞」(leading words)引導LLM向特定方向發展
低效 ❌:
# Write a simple python function that
# 1. Ask me for a number in mile
# 2. It converts miles to kilometers
更佳 ✅:
# Write a simple python function that
# 1. Ask me for a number in mile
# 2. It converts miles to kilometersimport
例子中,加入"import"(這是Python語言中,用於引入的語句),令LLM知道應該以Python 進行編寫。(同理,加入"SELECT",可以更好地讓LLM知道,這將會開始一個SQL語句)
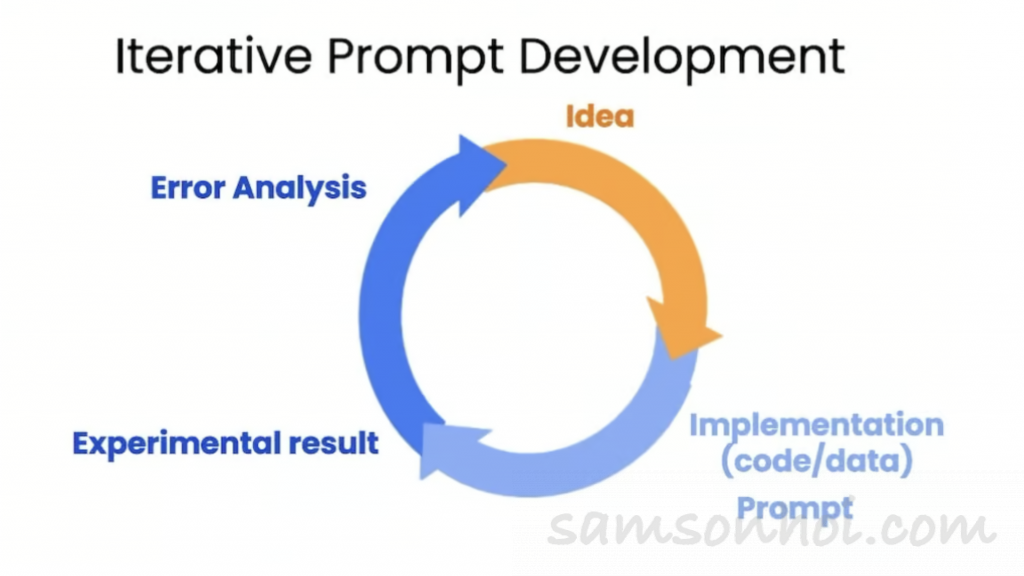
Iterative Prompt Development 迭代提示開發
在設計 Prompt 的過程中,很多時候並不會一次就完成整個 Prompt,
要根據結果再不斷調整 Prompt,直至達到最終結果,亦即為迭代提示開發(Iterative Prompt Development)。
調整過程中會遇到不少狀況,最常見的例如有:
- 解決文字過長
- 解決方法:限制 字數/句子數/字符數
- 回答時錯重點
- 解決方法:要求專注在與目標受眾相關的方面
- 描述表格所需要的維度
- 解決方式:要求在表格中 提煉 Extract 資訊並組織
- 產生幻覺(Hallucinations)
- 如果 Prompt 本身有部份內容是虛構的,與真實情況混合,令導致LLM產生「幻覺」,生成出一些虛構的答案。
- 避免方法是盡量找出相關資訊,然後基於這些相對準確的資訊再問問題。
LLM 四大能力
一般而言,LLM 通常有以下四大能力:Summarizing 總結、Inferring 推理、Transforming 變型、Expanding 擴充
- Summarizing 總結
- 用字上使用 提煉 Extract 總結文章比用 Summarize 效果更佳
- Inferring 推理
- Transforming 變型
- Expanding 擴充
總結
LLM 並非萬能魔法盒,它並不能全自動 100% 完美產生你所需要的內容,需要一些引導技巧,它才能表現得更好。掌握 Prompting 的原則和技巧將能夠更好地與 LLM 溝通。同時,LLM 通常具有的四大使用場景:Summarizing 總結、Inferring 推理、Transforming 變型、Expanding 擴充;然而模型本身也會存在一些限制,例如:Hallucinations(幻覺)、回答時錯重點 等等的情況,這在編寫 Prompt 的過程中將會不斷迭代和調整,這個過程叫做迭代提示開發。
在 AI 賦能的大時代,學會如何寫好 Prompt,從 LLM 獲得質量更高的回答。現已成為每個人的必修課。
本文寫於2023年06月23日,由於 AI 行業發展迅速,以上內容有機會有若干時間後會過時,甚至變得毫無意義。
本篇內容屬於個人總結分享,並不包含任何 AIGC 所生成的內容。